目录和相关资源
简单函数绘图语言解释器 Python实现—-语法分析篇
简单函数绘图语言解释器 Python实现—-语义分析&实现篇
GitHub开源完整代码
前言&概述
俺又来更新博客了,这次的内容是利用Python实现一个简单函数绘图语言解释器。其实项目本身已经完成了有一段时间了,但是出于期末考试等诸多原因(主要是因为懒)一直没有真正写成文章发上来,正好这次假期时间长,我也是在学校闲的要命,不如就趁着这个机会好好掰扯掰扯这个编译原理选做大作业。
首先要明确一点,什么是简单函数绘图语言?咱们先来看一段示例代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
rot is 0; origin is (0, 0); scale is (2,20); for T from 1 to 300 step 1 draw (t,-ln(t)); scale is (20,0.1); for T from 0 to 8 step 0.1 draw (t,exp(t)); scale is (2,1); for T from 0 to 300 step 1 draw (t,0); for T from 0 to 300 step 1 draw (0,t); for T from 0 to 120 step 1 draw (t,t); scale is (2,0.1); for T from 0 to 55 step 1 draw (t,-(t*t)); scale is (10,5); for T from 0 to 60 step 1 draw (t,sqrt(t)); |
我们可以看到,上面的语句中,主要出现了这么几个关键词:ROT、ORIGIN、SCALE、FOR,那么他们分别是什么意思呢?
- ROT语句:该语句的作用是控制逆时针角度旋转,如上述代码中的
rot is 0的意思便是逆时针旋转0°的含义 - ORIGIN语句:该语句的作用是将坐标系原点平移到横坐标和纵坐标规定的点处,如上述代码汇总的
origin is (0, 0)便是规定坐标(0, 0)为原点的含义。 - SCALE语句:该语句的作用是设置横坐标和纵坐标的比例,并将其按照相关比例因子进行缩放,如上述代码中的
scale is (2, 20)的含义是将横坐标和纵坐标的比例设置为1:10并放大2倍。 - FOR-DRAW语句:该语句是绘图的核心语句,主要作用是在坐标图上描点并绘图,通过step指定步长,如上述代码中的
for T from 1 to 300 step 1 draw (t,-ln(t));便是令T从1到300变化,步长为1,绘制出一系列坐标(t, -ln(t))
当然,我们的解释器还需要具备识别注释、出错处理等基本功能,下面是我实现过程中遵循的一些小的原则:
- 语句以分号结尾,处理过程中按从上到下的顺序进行处理
- 大小写不敏感,不管是关键字还是变量名都是如此(在读入时都转换成大写)
- 默认ROT旋转的方向为逆时针旋转
词法分析器实现
词法分析器由三个文件构成,分别是scanner_token.py、scannerprocess.py和testscanner.py
scanner_token.py (构造符号表和token类型)
该文件中给出了token的定义和可能出现的所有token类型,对于一些特殊token 类型,如sin, cos等,使用numpy对应的矩阵运算方法进行构造。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
from enum import Enum, auto import numpy as np Token_Type = Enum('Token_Type', ('ORIGIN', 'SCALE', 'ROT', 'IS', 'TO', 'STEP', 'DRAW', 'FOR', 'FROM', # 保留字 'T', # 参数 'SEMICO', 'L_BRACKET', 'R_BRACKET', 'COMMA', # 分隔符 'PLUS', 'MINUS', 'MUL', 'DIV', 'POWER', # 运算符 'FUNC', # 函数符 'CONST_ID', # 常数 'NONTOKEN', # 空记号 'ERRTOKEN')) # 出错记号 class Tokens: def __init__(self, type, lexeme, value, funcptr): self.lexeme = lexeme # 字符串属性 self.value = value # 常数值属性 self.funcptr = funcptr # 函数指针 if type in Token_Type: self.type = type # token类别 else: print("非法类型") # 构造符号表字典,包括常见的函数名、关键字和变量标记 TokenTab = dict([ ('PI', Tokens(Token_Type.CONST_ID, "PI", 3.1415926, None)), ('E', Tokens(Token_Type.CONST_ID, "E", 2.71828, None)), # 左key右value ('T', Tokens(Token_Type.T, 'T', 0.0, None)), ('SIN', Tokens(Token_Type.FUNC, 'SIN', 0.0, np.sin)), # 不能用math库,无法进行矩阵运算 ('COS', Tokens(Token_Type.FUNC, 'COS', 0.0, np.cos)), ('TAN', Tokens(Token_Type.FUNC, 'TAN', 0.0, np.tan)), ('LN', Tokens(Token_Type.FUNC, 'LN', 0.0, np.log)), ('EXP', Tokens(Token_Type.FUNC, 'EXP', 0.0, np.exp)), ('SQRT', Tokens(Token_Type.FUNC, 'SQRT', 0.0, np.sqrt)), ('ORIGIN', Tokens(Token_Type.ORIGIN, 'ORIGIN', 0.0, None)), ('SCALE', Tokens(Token_Type.SCALE, 'SCALE', 0.0, None)), ('ROT', Tokens(Token_Type.ROT, 'ROT', 0.0, None)), ('IS', Tokens(Token_Type.IS, 'IS', 0.0, None)), ('FOR', Tokens(Token_Type.FOR, 'FOR', 0.0, None)), ('FROM', Tokens(Token_Type.FROM, 'FROM', 0.0, None)), ('TO', Tokens(Token_Type.TO, 'TO', 0.0, None)), ('STEP', Tokens(Token_Type.STEP, 'STEP', 0.0, None)), ('DRAW', Tokens(Token_Type.DRAW, 'DRAW', 0.0, None)) ]) |
scannerprocess.py (构造词法分析器)
主要实现词法分析过程,其核心在于GetToken方法的设计。其设计的核心原 理在于对于每一类字符的正规式的构造,并依据正规式给出对应类型的识别方法。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 |
import scanner_token import os class Scanner: def __init__(self, f_name): # 初始化scanner self.LineNo = 0 # 行号标记 self.TokenBuffer = '' # 待记号缓存区 self.f_name = f_name # 输入文件目录 if os.path.exists(self.f_name): self.f_ptr = open(self.f_name, "r") else: self.f_ptr = None def CloseScanner(self): # 关闭词法分析器 if self.f_ptr is not None: self.f_ptr.close() def GetChar(self): Char = self.f_ptr.read(1) # 读取一个字符 return Char.upper() def BackChar(self, Char): # 回退一个字符 if Char != '': self.f_ptr.seek(self.f_ptr.tell() - 1) def AddCharTokenString(self, Char): # 加入缓存区 self.TokenBuffer += Char def EmptyTokenString(self): # 情况缓存区 self.TokenBuffer = '' def JudgeKeyToken(self): # 判断Token是否为关键字 Token = scanner_token.TokenTab.get(self.TokenBuffer,scanner_token.Tokens(scanner_token.Token_Type.ERRTOKEN, self.TokenBuffer,0.0, None)) return Token def GetToken(self): # 关键部分,获取token,在原理上是由DFA生成并实现。 Char = '' token = '' self.EmptyTokenString() # 清空缓冲区 while True: # 处理文件结束符、回车、空格等特殊字符 Char = self.GetChar() # 读一个字符 if Char == '': token = scanner_token.Tokens(scanner_token.Token_Type.NONTOKEN, Char, 0.0, None) return token if Char == '\n': self.LineNo += 1 if ~Char.isspace(): break self.AddCharTokenString(Char) # 不是特殊字符就加入缓冲区 if Char.isalpha(): # 判断字母 while True: # 一直读取,直到读到非字符或数字的字符 Char = self.GetChar() if Char.isalnum(): self.AddCharTokenString(Char) else: break self.BackChar(Char) token = self.JudgeKeyToken() token.lexme = self.TokenBuffer return token elif Char.isdigit(): # 判断数字 while True: # 整数部分 Char = self.GetChar() if Char.isdigit(): self.AddCharTokenString(Char) else: break if Char == '.': # 小数点 self.AddCharTokenString(Char) while True: # 小数部分 Char = self.GetChar() if Char.isdigit(): self.AddCharTokenString(Char) else: break self.BackChar(Char) token = scanner_token.Tokens( scanner_token.Token_Type.CONST_ID, self.TokenBuffer, float(self.TokenBuffer), None) return token else: if Char == ';': # 语句结束检查 token = scanner_token.Tokens(scanner_token.Token_Type.SEMICO, Char, 0.0, None) elif Char == '(': # 左括号 token = scanner_token.Tokens(scanner_token.Token_Type.L_BRACKET, Char, 0.0, None) elif Char == ')': # 右括号 token = scanner_token.Tokens(scanner_token.Token_Type.R_BRACKET, Char, 0.0, None) elif Char == ',': token = scanner_token.Tokens(scanner_token.Token_Type.COMMA, Char, 0.0, None) elif Char == '+': token = scanner_token.Tokens(scanner_token.Token_Type.PLUS, Char, 0.0, None) elif Char == '-': # 可能是单行注释或减号 Char = self.GetChar() if '-' == Char: while Char != '\n' and Char != '': Char = self.GetChar() self.BackChar(Char) return self.GetToken() else: self.BackChar(Char) token = scanner_token.Tokens(scanner_token.Token_Type.MINUS, '-', 0.0, None) elif Char == '/': # 可能是单行注释或除号 Char = self.GetChar() if Char == '/': while Char != '\n' and Char != '': Char = self.GetChar() self.BackChar(Char) return self.GetToken() else: self.BackChar(Char) token = scanner_token.Tokens(scanner_token.Token_Type.DIV, '/', 0.0, None) elif Char == '*': # 可能是乘号或乘方 Char = self.GetChar() if Char == '*': token = scanner_token.Tokens(scanner_token.Token_Type.POWER, '**', 0.0, None) else: self.BackChar(Char) token = scanner_token.Tokens(scanner_token.Token_Type.MUL, '*', 0.0, None) else: if Char == ' ' or Char == '\n': return self.GetToken() else: token = scanner_token.Tokens(scanner_token.Token_Type.ERRTOKEN, Char, 0.0, None) return token |
testscanner.py
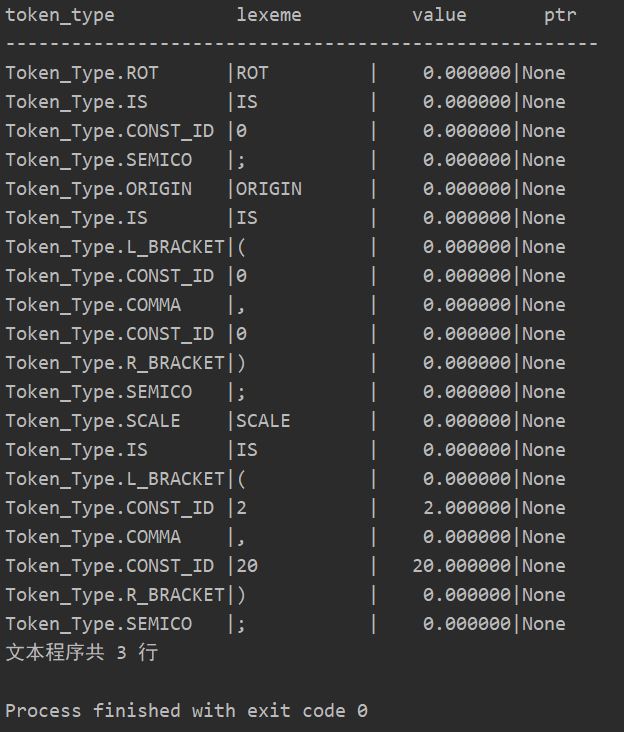
该文件负责对scanner进行测试,输入graphic.txt文件,输出由scanner检测到的记号流构成的记号表,通过测试scanner,为后续创建语法树打基础。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import scanner_token import scannerprocess f_name = 'graphic.txt' scanner = scannerprocess.Scanner(f_name) if scanner.f_ptr is not None: print("token_type lexeme value ptr") print("------------------------------------------------------") while True: token = scanner.GetToken() if token.type != scanner_token.Token_Type.NONTOKEN: print("{:20s}|{:12s}|{:12f}|{}".format(token.type, token.lexeme, token.value, token.funcptr)) else: break print("文本程序共", scanner.LineNo, "行") else: print("打开文件失败") |
运行结果如下所示: