目录和相关资源
简单函数绘图语言解释器 Python实现—-概述&词法分析篇
简单函数绘图语言解释器 Python实现—-语义分析&实现篇
GitHub开源完整代码
前言
上一次篇博客里,我们一起构造了代码的词法分析器,可以看到,经过词法分析器的处理,我们可以将代码中的每一个词语都有效的解析出来,识别出变量、关键字、常数等信息。这也就引出了我们的下一个问题,怎样构造一个语法分析器,使得这些词语能够有效的被组织起来,形成实际具有意义的语句呢?
在编译原理课程里,我们学过了文法和语法树的概念(如果你在看这里但是对这些概念不熟悉,建议回去看一下课本再回来看代码),根据特定的文法,我们可以从产生式生成不同语句,放在这里来讲,就是每一个关键字都有其对应的语法规则,如ORIGIN IS (横坐标,纵坐标);, FOR T FROM 起点 TO 终点 STEP 步长 DRAW(横坐标, 纵坐标);。也就是说,我们需要根据这些语法规则,将词法分析器返回给我们的结果进行组合,将零散的词语组合成有实际意义语句。
词法分析器实现
语法分析器由parser_node.py、parserprocess.py和testparser.py构成。
parser_node.py (构造语法树节点)
该文件给出了语法树节点 ExprNode 的构造方法,在确定每一个运算符的种类后,对 于双目运算符,给该节点分配左右子树,对于函数类型,给该节点分配函数指针和middle内容。构造GetValue方法,针对每一个节点给出其结果的运算方式,将其存储在矩阵中,为后续过程实现画图提供方便。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
import scanner_token class ExprNode(object): def __init__(self, item): self.item = item # 确定双目运算符 if self.item == scanner_token.Token_Type.PLUS or self.item == scanner_token.Token_Type.MINUS or self.item == scanner_token.Token_Type.MUL or self.item == scanner_token.Token_Type.DIV or self.item == scanner_token.Token_Type.POWER: self.left = None self.right = None elif self.item == scanner_token.Token_Type.FUNC: # 函数类型 self.Func_ptr = None self.middle = None self.value = None def __str__(self): return str(self.item) def GetValue(self): # 依据不同的操作符进行运算 if self.item == scanner_token.Token_Type.PLUS: self.value = self.right.value + self.left.value elif self.item == scanner_token.Token_Type.MINUS: self.value = self.left.value - self.right.value elif self.item == scanner_token.Token_Type.MUL: self.value = self.right.value * self.left.value elif self.item == scanner_token.Token_Type.DIV: self.value = self.left.value / self.right.value elif self.value == scanner_token.Token_Type.POWER: self.value = self.left.value ** self.right.value elif self.item == scanner_token.Token_Type.FUNC: self.value = self.Func_ptr(self.middle.value) return self.value |
parserprocess.py
该主要实现了语法分析的过程,其中语法树的构造,语法的识别,报错信息的提 示等功能,是整个函数绘图语言解释器的核心部分,也是最难的部分。 实现该部分的核心思路在于针对不同的语句提供一种构造语法树的方法,针对每一种语句,如 OriginStatement,ScaleStatement,ForStatement构建其语法分析过程,并使得程序可以在读 到错误语法是给出对应行号的报错。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 |
import numpy as np import sys import parser_node import scanner_token import scannerprocess class Parser(object): def __init__(self, scanner): self.scanner = scanner # 词法分析器初始化 self.token = None self.Parameter = 0 self.x_origin = 0 self.y_origin = 0 self.x_scale = 1 self.y_scale = 1 self.rot = 0 self.x_ptr = None self.y_ptr = None self.Tvalue = 0 def enter(self, x): # 进入语句 print("进入", str(x)) def back(self, x): # 离开语句 print("离开", str(x)) def call_match(self, x): # 匹配token类型 print('匹配token', str(x)) def Tree_trace(self, x): # 打印语法树 self.PrintSyntaxTree(x, 1) def FetchToken(self): # 调用GetToken方法 self.token = self.scanner.GetToken() while self.token.type == scanner_token.Token_Type.NONTOKEN: self.token = self.scanner.GetToken() if self.token == scanner_token.Token_Type.ERRTOKEN: print(self.token.type) print("出错行号:", self.scanner.LineNo, " 记号错误 ", self.token.lexeme) self.scanner.CloseScanner() sys.exit(1) def MatchToken(self, token_type): # 匹配token符号,带出错处理 if self.token.type != token_type: print(self.token.type) print("出错行号:", self.scanner.LineNo, " 与期望记号不符 ", self.token.lexeme) self.scanner.CloseScanner() sys.exit(1) if token_type == scanner_token.Token_Type.SEMICO: self.scanner.f_ptr.readline() last = self.scanner.f_ptr.tell() next_line = self.scanner.f_ptr.readline() if len(next_line) == 0: return else: self.scanner.f_ptr.seek(last) self.FetchToken() def PrintSyntaxTree(self, root, indent): # 打印语法树 for i in range(indent): # 控制树缩进 print('\t', end=' ') if root.item == scanner_token.Token_Type.PLUS: print('+ ') elif root.item == scanner_token.Token_Type.MINUS: print('- ') elif root.item == scanner_token.Token_Type.MUL: print('* ') elif root.item == scanner_token.Token_Type.DIV: print("/ ") elif root.item == scanner_token.Token_Type.POWER: print("** ") elif root.item == scanner_token.Token_Type.FUNC: print("{} ".format(root.Func_ptr)) elif root.item == scanner_token.Token_Type.CONST_ID: print('{:5f} '.format(root.value)) elif root.item == scanner_token.Token_Type.T: print('{} '.format(root.value)) else: print("节点类型错误") sys.exit(0) if root.item == scanner_token.Token_Type.CONST_ID or root.item == scanner_token.Token_Type.T: return # 常数和参数是叶子节点 elif root.item == scanner_token.Token_Type.FUNC: self.PrintSyntaxTree(root.middle, indent + 1) # 函数只有一个孩子节点 else: # 先序遍历 self.PrintSyntaxTree(root.left, indent + 1) self.PrintSyntaxTree(root.right, indent + 1) def Parser(self): # 语法分析器本体 self.enter("Parser") if self.scanner.f_ptr is None: print("文件打开错误") else: self.FetchToken() # 获取第一个token self.Program() # 开始递归下降分析 self.scanner.CloseScanner() # 关闭词法分析器 self.back("Parser") # 退出语法分析器 def Program(self): self.enter("Program") while self.token.type != scanner_token.Token_Type.SEMICO: self.Statement() self.MatchToken(scanner_token.Token_Type.SEMICO) self.call_match("; ") self.back("Program") def Statement(self): # 为每一个语句转进每一种文法 self.enter("Statement") if self.token.type == scanner_token.Token_Type.ORIGIN: self.OriginStatement() elif self.token.type == scanner_token.Token_Type.SCALE: self.ScaleStatement() elif self.token.type == scanner_token.Token_Type.FOR: self.ForStatement() elif self.token.type == scanner_token.Token_Type.ROT: self.RotStatement() elif self.token.type == scanner_token.Token_Type.CONST_ID or self.token.type == scanner_token.Token_Type.L_BRACKET or self.token.type == scanner_token.Token_Type.MINUS: self.Expression() else: print(self.token.type) print("出错行号:", self.scanner.LineNo, " 与期望记号不符 ", self.token.lexeme) self.scanner.CloseScanner() sys.exit(1) self.back("Statement") def OriginStatement(self): # origin语句 self.enter("OriginStatement") self.MatchToken(scanner_token.Token_Type.ORIGIN) self.call_match("ORIGIN") self.MatchToken(scanner_token.Token_Type.IS) self.call_match("IS") self.MatchToken(scanner_token.Token_Type.L_BRACKET) self.call_match("(") temp = self.Expression() self.x_origin = temp.GetValue() self.MatchToken(scanner_token.Token_Type.COMMA) self.call_match(",") temp = self.Expression() self.y_origin = temp.GetValue() self.MatchToken(scanner_token.Token_Type.R_BRACKET) self.call_match(")") self.back("OriginStatement") def ScaleStatement(self): # scale语句 self.enter("ScaleStatement") self.MatchToken(scanner_token.Token_Type.SCALE) self.call_match("SCALE") self.MatchToken(scanner_token.Token_Type.IS) self.call_match("IS") self.MatchToken(scanner_token.Token_Type.L_BRACKET) self.call_match("(") temp = self.Expression() self.x_scale = temp.GetValue() self.MatchToken(scanner_token.Token_Type.COMMA) self.call_match(",") temp = self.Expression() self.y_scale = temp.GetValue() self.y_origin = temp.GetValue() self.MatchToken(scanner_token.Token_Type.R_BRACKET) self.call_match(")") self.back("ScaleStatement") def ForStatement(self): # for-draw语句 self.enter("ForStatement") start = 0.0 end = 0.0 step = 0.0 self.MatchToken(scanner_token.Token_Type.FOR) self.call_match("FOR") self.MatchToken(scanner_token.Token_Type.T) self.call_match("T") self.MatchToken(scanner_token.Token_Type.FROM) self.call_match("FROM") start_ptr = self.Expression() start = start_ptr.GetValue() self.MatchToken(scanner_token.Token_Type.TO) self.call_match("TO") end_ptr = self.Expression() end = end_ptr.GetValue() self.MatchToken(scanner_token.Token_Type.STEP) self.call_match("STEP") step_ptr = self.Expression() step = step_ptr.GetValue() self.Tvalue = np.arange(start, end, step) self.MatchToken(scanner_token.Token_Type.DRAW) self.call_match("DRAW") self.MatchToken(scanner_token.Token_Type.L_BRACKET) self.call_match("(") self.x_ptr = self.Expression() self.x_ptr = self.x_ptr.value self.MatchToken(scanner_token.Token_Type.COMMA) self.call_match(",") self.y_ptr = self.Expression() self.y_ptr = self.y_ptr.value self.MatchToken(scanner_token.Token_Type.R_BRACKET) self.call_match(")") self.back("ForStatement") def RotStatement(self): # rot语句 self.enter("RotStatement") self.MatchToken(scanner_token.Token_Type.ROT) self.call_match("ROT") self.MatchToken(scanner_token.Token_Type.IS) self.call_match("IS") temp = self.Expression() self.rot = temp.GetValue() self.back("RotStatement") def Expression(self): # 识别由正负号或无符号开头,以加减号连接的语法 self.enter("Expression") left = self.Term() while self.token.type == scanner_token.Token_Type.PLUS or self.token.type == scanner_token.Token_Type.MINUS: temp = self.token.type self.MatchToken(temp) right = self.Term() left = self.MakeExprNode(temp, left, right) self.Tree_trace(left) self.back("Expression") return left def Term(self): # 识别以乘除号连接的语法 left = self.Factor() while self.token.type == scanner_token.Token_Type.MUL or self.token.type == scanner_token.Token_Type.DIV: temp = self.token.type self.MatchToken(temp) right = self.Factor() left = self.MakeExprNode(temp, left, right) return left def Factor(self): # 识别一个标识符或数字、或括号内 if self.token.type == scanner_token.Token_Type.PLUS: self.MatchToken(scanner_token.Token_Type.PLUS) right = self.Factor() left = None right = self.MakeExprNode(scanner_token.Token_Type.PLUS, left, right) elif self.token.type == scanner_token.Token_Type.MINUS: self.MatchToken(scanner_token.Token_Type.MINUS) right = self.Factor() left = parser_node.ExprNode(scanner_token.Token_Type.CONST_ID) left.value = 0.0 right = self.MakeExprNode(scanner_token.Token_Type.MINUS, left, right) else: right = self.Component() return right def Component(self): # 识别幂次 left = self.Atom() if self.token.type == scanner_token.Token_Type.POWER: self.MatchToken(scanner_token.Token_Type.POWER) right = self.Component() left = self.MakeExprNode(scanner_token.Token_Type.POWER, left, right) return left def Atom(self): # 识别函数、常数、参数 if self.token.type == scanner_token.Token_Type.CONST_ID: temp = self.token.value self.MatchToken(scanner_token.Token_Type.CONST_ID) address = self.MakeExprNode_CONST(scanner_token.Token_Type.CONST_ID, temp) elif self.token.type == scanner_token.Token_Type.T: self.MatchToken(scanner_token.Token_Type.T) if len(self.Tvalue) == 1: address = self.MakeExprNode_CONST(scanner_token.Token_Type.T, 0.0) else: address = self.MakeExprNode_CONST(scanner_token.Token_Type.T, self.Tvalue) elif self.token.type == scanner_token.Token_Type.FUNC: temp_ptr = self.token.funcptr self.MatchToken(scanner_token.Token_Type.FUNC) self.MatchToken(scanner_token.Token_Type.L_BRACKET) self.call_match("(") temp = self.Expression() address = self.MakeExprNode(scanner_token.Token_Type.FUNC, temp_ptr, temp) self.MatchToken(scanner_token.Token_Type.R_BRACKET) self.call_match(")") elif self.token.type == scanner_token.Token_Type.L_BRACKET: self.MatchToken(scanner_token.Token_Type.L_BRACKET) self.call_match("(") address = self.Expression() self.MatchToken(scanner_token.Token_Type.R_BRACKET) self.call_match(")") else: print(self.token.type) print("出错行号:", self.scanner.LineNo, " 与期望记号不符 ", self.token.lexeme) self.scanner.CloseScanner() sys.exit(1) return address def MakeExprNode(self, item, left, right): # 生成节点 ExprPtr = parser_node.ExprNode(item) if item == scanner_token.Token_Type.FUNC: ExprPtr.Func_ptr = left ExprPtr.middle = right else: ExprPtr.left = left ExprPtr.right = right ExprPtr.GetValue() # 更新Value return ExprPtr def MakeExprNode_CONST(self, item, value): # 常数和变量的节点,叶子结点 ExprPtr = parser_node.ExprNode(item) ExprPtr.value = value return ExprPtr |
testparser.py
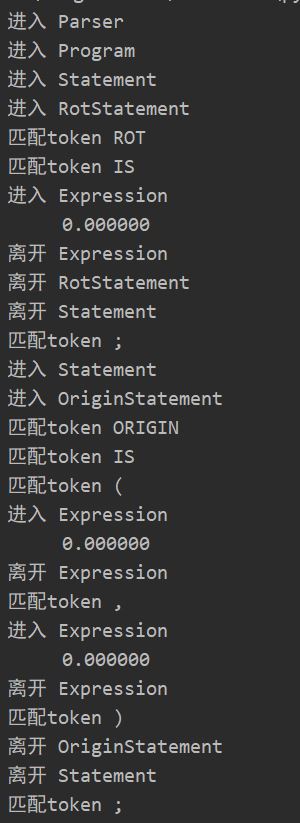
该文件主要功能是测试语法分析的过程是否正确,输入graphic.txt文件,输出构造出的语法树结构,方便进行下一步操作。
|
1 2 3 4 5 6 7 8 9 |
import scannerprocess import parserprocess file_name = 'graphic.txt' scanner = scannerprocess.Scanner(file_name) parser = parserprocess.Parser(scanner) parser.Parser() |
可能的运行结果如下: